Understanding Overfitting in Random Forest and Mitigation Strategies with Regularization – By Tewogbade Shakir
Overfitting is a common challenge in machine learning, where a model performs exceptionally well on training data but fails to generalize to unseen data. This phenomenon can significantly hinder the model’s predictive capabilities in real-world applications. Random Forest, a powerful ensemble learning method, is not immune to overfitting. In this discussion, we will explore the concept of overfitting in Random Forest, analyse learning curves to identify overfitting, and highlight how regularization techniques can mitigate this issue.
Overfitting in Random Forest
Random Forest is an ensemble method that builds multiple decision trees and merges them to get a more accurate and stable prediction. Despite its robustness, Random Forest can overfit, especially when the trees are very deep, capturing noise along with the signal in the training data.
Identifying Overfitting
The learning curves are a crucial diagnostic tool to identify overfitting. A learning curve plots the model’s performance on the training set and a validation set over a varying number of training instances. The gap between the training and validation performance can reveal overfitting
Analysing Learning Curves
Below are three learning curve analyses demonstrating different degrees of overfitting in Random Forest models.
High Overfitting:
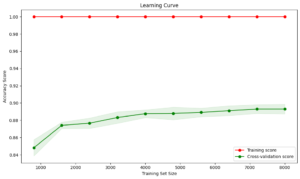
Training Accuracy: Close to 100%
Validation Accuracy: Significantly lower, around 88%
Interpretation: The model is memorizing the training data and failing to generalize.
Moderate Overfitting:
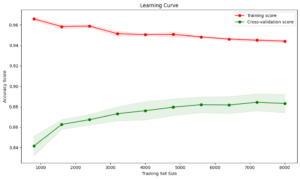
Training Accuracy: Around 95%
Validation Accuracy: Around 88%, with a decreasing trend
Interpretation: Some improvements with regularization, but still not optimal.
Reduced Overfitting:
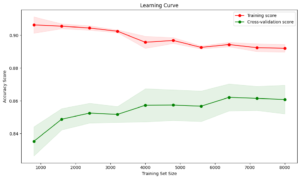
Training Accuracy: Around 90%
Validation Accuracy: Around 86%, with smaller gap
Interpretation: Better balance between bias and variance, indicating improved generalization.
Mitigating Overfitting with Regularization
Regularization techniques can help control the complexity of the model, thereby reducing overfitting. Here are some effective strategies:
*Limit the Maximum Depth of Trees (max_depth)
Restricting the depth of each tree prevents the model from learning too many details and noise from the training data.
| Python Code |
| RandomForestClassifier(max_depth=7, …) |
*Increase Minimum Samples for Split (min_samples_split)
Ensuring a minimum number of samples required to split an internal node helps in making the model less sensitive to noise.
| Python Code |
| RandomForestClassifier(min_samples_split=15, …) |
*Increase Minimum Samples for Leaf Nodes (min_samples_leaf)
Setting a minimum number of samples for leaf nodes ensures that each leaf has sufficient data, thus avoiding overly specific rules.
| Python Code |
| RandomForestClassifier(min_samples_leaf=10, …) |
*Control the Number of Features Considered for Splitting (max_features)
Limiting the number of features considered at each split can reduce overfitting by ensuring that splits are made on a subset of features.
| Python Code |
| RandomForestClassifier(max_features=’sqrt’, …) |
Case Study: Applying Regularization
We applied the above regularization techniques to a Random Forest model and observed the learning curves. The resulting curves demonstrated reduced overfitting, as indicated by a smaller gap between training and validation accuracy and a more stable validation performance.
| Python Code |
| from sklearn.ensemble import RandomForestClassifier
# Regularized Random Forest model rf_model = RandomForestClassifier( n_estimators=100, max_depth=7, min_samples_split=15, min_samples_leaf=10, max_features=’sqrt’, random_state=42 ) # Training and evaluating the model…
# Generating learning curves… |
Conclusion
Overfitting is a critical issue in Random Forest models, but it can be effectively mitigated with appropriate regularization techniques. By limiting the complexity of the trees, ensuring sufficient samples at splits and leaves, and controlling the number of features considered, we can improve the model’s generalization capabilities. The use of learning curves is instrumental in diagnosing overfitting and guiding the application of regularization methods. Through careful tuning and validation, it is possible to achieve a balanced model that performs well on both training and unseen data.